
My guest, Dr. Abhishek Puri, is a Radiation Oncologist with an interest in AI and healthcare policy. He blogs at www.radoncnotes.com and tweets as “radoncnotes”.
We wrote a column in Open magazine, at https://openthemagazine.com/columns/artificial-intelligence-like-allopathy/ which looks at what can be gleaned from our experiences with Allopathy and how these can be translated to how we deal with generative AI. In this video, we summarize our findings.
Of particular note is the fact that chatGPT, in summarizing our article, completely ignores Ayurveda, despite the fact that we do mention it several times. As Abhishek points out, this suggests the eclipse of Indian knowledge altogether, as western biases creep into epistemology: Indian knowledge simply doesn’t exist as far as the western Internet is concerned. We have seen this before in how Indian mathematical advances and scientific advances have been either erased, or generously ‘awarded’ to the Greeks or Chinese or someone else.
Although our purpose in writing this essay was to consider how statistics-based (ie. stochastic) systems work when we expect them, unconsciously, to be predictable in all cases (ie. deterministic), this issue of the erasure of Indian knowledge is a particularly important concern. Others have also expressed the concern that with generative AI’s mimetic skills, copyright may become a thing of the past.
Intellectual Property Rights need to be protected, and in particular, data. India needs to develop its own generative AI systems: not the large language models (these are available in open source), but the data to train them with an Indian context and in multiple Indian languages. This is a major challenge.
Modern western medicine (also known as ‘Allopathy’) has been in the news for several years, thanks to the viral COVID-19 pandemic. Allopathy (we shall use this term here to distinguish it from Ayurveda and avoid value judgments such as ‘modern’) has admittedly led to an enormous improvement in human health and longevity, although other factors such as hygiene play a role. It has also become one of the most technology-heavy areas of human endeavor, and that is reflected in the galloping costs of healthcare.
Today, there is a huge buzz about artificial intelligence, specifically generative AI, as exemplified by chatGPT, a chatbot that simulates human conversations. It has become the fastest adopted consumer product in history, and it is at the level of inflated expectations in the Gartner Hype Cycle. There is a cautionary tale about the Metaverse which was last year’s darling, but has sunk without a trace. Likewise, AI hype could soon fall into the trough of disillusionment.

Anyway, there is an intriguing and fundamental connection between the two, with lessons from one for the other. However, there are indications that the current trajectory may produce diminishing returns. Is there any benefit for India to succumb to the siren song of chatGPT? What are the potential downsides? There’s an element of caveat emptor: buyer beware.
The medical miracle: has it reached the end of the line?
Life expectancy across the world has improved dramatically over the past hundred years. Even for India, which ranks at a lowly 136 in this list published by Worldometer, the numbers are a respectable 70 years or so, way ahead of the mid-30s in 1947.
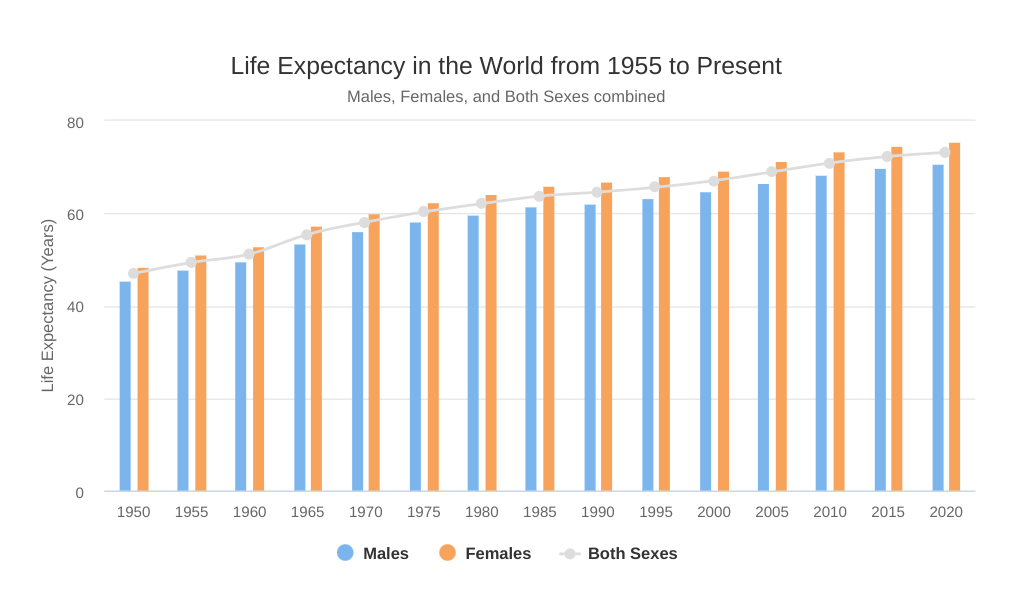
This can be legitimately termed a miracle and encapsulates a tremendous improvement in human welfare, health, and well-being. A good bit of it can be attributed to Allopathy, modern pharmacopoeia (especially antibiotics), vaccines, and surgical innovations, but we must also credit general affluence and especially hygiene. Clean water, mechanisms to reduce vector-borne diseases, and large-scale improvement in waste management have all contributed. Awareness of a healthier lifestyle has also helped: eg, reducing smoking, drinking, meat consumption and improving exercise levels. But we are reaching the plateau; once the easy gains have been made, it becomes harder to achieve the next improvement.
However, there are downsides, too. The failures of Allopathy have a common theme of fundamental misunderstandings of illness and its biomarkers, and excessive statistical analysis. This is compounded by conflicts of interest and bureaucratisation, leading to “analysis-paralysis” with well-intentioned policies producing unintended consequences.
The Framingham Heart Study in 1948 introduced the concept of causation, but the researchers did not focus on the multifactorial process of disease. Various random events interact with physical organisms to produce disease. The science of uncertainty deals with randomness, and scientific proofs are subject to change with new discoveries. Allopathy uses statistics to determine the boundary between health and disease, and outcomes are based on the interaction of an individual's inherent phenotype and the environment.
This reductionist view of medicine sharpened into focus in the 1990's, when decision-making based on empirical evidence from randomized studies replaced deductive reasoning from mechanistic theories rooted in basic sciences.
That is not to dismiss empirical evidence. There is the salutary tale of poor Ignaz Semmelweis in 1850’s Austria.
He observed that hand washing between deliveries in obstetric wards reduced mortality, but had no theoretical explanation that fit with current scientific opinion. This led to him being sidelined (and in fact he was committed to a lunatic asylum). He was vindicated posthumously, after ‘germ-theory’ provided cause and effect.
The question is, what is the right evidence from homogeneous correlative studies, to make decisions about patients who don't fit textbook manifestations? Highly controlled trials don’t necessarily explain these phenomena.
Artificial Intelligence has similar issues. Our understanding of the world is shaped by our ‘factual beliefs’ (and desires). AI assumes that our thought processes are merely processed extraneous information. The differences between human thought and AI become apparent when we consider what an error is. Human error is made intelligible by regarding it in the context of perception and past experiences.
A computer error may not be intelligible, because it cannot make judgments or explain the thought process. Inferential knowledge must be explained in its grammar and universal laws, to be understood by humans without scope for misinterpretation. Current developers of AIs anthropomorphize their thinking process, in a shallow mimicking of humans, but without offering an understanding of how its components fit together. However, AIs that think entirely unlike humans are also in the works e.g. AlphaZero that plays chess using a Monte Carlo Tree Search in ways that are vastly different from human players.
The parallel between Allopathy and AI is that they are both stochastic, that is, both are likely to produce some outputs and less likely to produce others for a given input. The process is unlikely to be deterministic for either Allopathy or generative AI. This explains the dichotomy between expected versus desired outcomes when viewed from a reductionist lens. Correlations do not prove causation. For example, heart dysfunction correlates with raised cholesterol and blood pressure, but this is only a statistical marker with little evidence that lowering either decreases the risk of cardiovascular morbidity: thus no cause-effect.
The result is that we are spending ever more money, without getting commensurate returns. Healthcare costs in laissez faire America have risen sharply, yet Americans are not healthy.
The US spent an estimated $12,318 per capita, which also represents over-bureaucratisation passing off as “administrative costs”. The US has the lowest life expectancy (78.8 years) and highest infant mortality (5.8 deaths per 1000 live births) of 11 developed countries, despite spending twice as much as the other countries. The US workforce (2.6 physicians and 11.1 nurses per 1000) was comparable to others.

The other option, socialised medicine in countries like the UK creates a lack of accessibility to healthcare, as patients have to wait endlessly. In addition, recent data shows they had 250,000 more deaths from all causes than expected in the last decade. The UK has lost ground on longevity, which hides real flaws. What could these be?

The politicisation of science during the pandemic turned it into a culture war. The New Statesman carried an op-ed by Phillip Ball, who described the “strange insouciance in the UK scientific community” for the complicity or unwillingness of science to stand up to poor political decisions on pandemic response. There was too much emphasis on mathematical modelling and not enough on feedback from frontline healthcare workers.
There are two possible culprits: one is the Cartesian reductionist axiom in western science, which holds that by endlessly reducing everything to its smallest component, there will be perfect knowledge and understanding. This of course runs afoul of the Uncertainty Principle, and, worse, ignores the entire notion of emergent intelligence, that is, the ‘wisdom of crowds’.
But Allopathy's greater issue is that it depends on statistical correlation. The gold standard for drug efficacy, randomised controlled trials or RCT, only allows for correlation, which could be spurious. Hypothetically, if an RCT shows 70% probability of a drug curing a disease, what happens if you personally fall in the unfortunate 30%? Should you take that drug? Do you have a choice? What happens when you take the drug, and it does not work on you?
No one has proved that the COVID-19 vaccines actually prevent the disease. Therefore, it could be argued that vaccination has nothing to do with the virus, and that vaccinated people who survived the disease did so for other reasons that nobody measured.
Unlike Allopathy, there is a clear ‘theory of disease’ in Ayurveda: the imbalance of the doshas. Ayurveda pinpoints causation, while Allopathy is content with correlation, which makes the latter stochastic, and not deterministic, which would be if there were an evident cause-effect relationship.
There’s a very good philosophical argument as to whether empirical truth is superior to, or at least equal to, axiomatic truth. But that is a question for another time. Here, what is relevant is that probability and statistics are at the core of modern Allopathy, which leaves large gaps (and treatment protocols that are a bit of a shot in the dark).
There is also a crisis of trust. The Economist magazine, in a long-read piece, Doctored Data, pointed out that many biomedical research papers present non-reproducible results; some papers reek of outright fraud, and others of massaging of data to get positive results. A case can be made that the entire COVID-19 origin theory was a triumph of narrative-building based on false assumptions (lab-leak being dismissed in demeaning terms until one fine day it isn’t, way after the horse has bolted, so to speak).
Generative AI (such as ChatGPT) suffers from the same problems as Allopathy, and more.
ChatGPT is epochal in the genesis of machine learning, because it discovered human patterns of speech and thinking. This is a class of machine learning called “Large Language Models” (LLM) that uses statistics to predict the next word in a sequence. It uses an encoder for input data and decoder for output sequences. It can give varying weight to different parts of the input in relation to any position of language sequence to infer meaning and context. It results in an output with a new linear projection of the query, key, and value vectors, in effect, with a dramatic improvement in reasoning, reading and comprehension.
It takes an effort of will to remember that it, however, doesn’t have any clue of what it’s talking about. It has no consciousness or context. All it’s doing is stringing together words with a high probability of belonging next to each other, based on a trillion fragments of text it has seen.
In many cases, this is good enough. But are you willing to bet on it? Part of the problem is the biases in the training data. For instance, ChatGPT is trained on text, acquired by scraping the Internet. How much of this is inaccurate? ChatGPT has no idea. Furthermore, it has been known to make up information (‘AI-hallucinations’). For instance, it announced that the linguist Noam Chomsky was dead, and created ‘references’ to back up its assertion.
Chomsky, who is one of the luminaries of language theory, is very much alive, and dismisses ChatGPT. In a recent essay in the NYT titled The False Promise of ChatGPT, he suggests that humans comprehend grammar as “a stupendously sophisticated system of logical principles and parameters” that enables them to create complex models of reality. Machines simply cannot do this, or at least cannot create the models that humans can. Therefore, he asserts, “the predictions of machine learning systems will always be superficial and dubious”.
Grammar has always been the bane of school life, but it's worth noting that Panini's context-free grammars, first postulated around 2500 years ago in the Ashtadhyayi, are critical for computer programming. Here’s what linguist Leonard Bloomfield said about Paninian Sanskrit: “The descriptive grammar of Sanskrit, which Panini brought to its perfection, is one of the greatest monuments of human intelligence and an indispensable model for the description of languages''. Yes, the Grand Unified Theory of Language.
Chomsky quotes Karl Popper: “We do not seek highly probable theories but explanations; that is to say, powerful and highly improbable theories.” Precisely: we want causation.
A chess game between ChatGPT and a high-quality program surprised the latter because ChatGPT made illegal moves despite being trained for the rules. When its pieces were captured, it simply re-materialized them elsewhere on the board! This is unreliable behaviour for a trusted application.
Chomsky also worries about the ethics of chatbots, for example Microsoft's Tay, which had to be deactivated in 2016 after it became racist and misogynist. He concludes: “Given the amorality, faux science and linguistic incompetence of these systems, we can only laugh or cry at their popularity”.
AIs do not – and cannot – give you an audit trail of how they arrived at a particular solution. A forensic analysis of what went wrong can't be done if something does go wrong: was it the data/text sets it was trained on? Was it unconscious bias on the part of the programmers?
Caveat emptor–India and generative AI: Neocolonialism via data?
Without transparency, chatbots will likely include datasets (or literature) harmful to Indian interests, generating new myths and values that alter the Indic narrative. Rajiv Malhotra's book Artificial Intelligence and the Future of Power: 5 battle grounds discusses in detail the dangers of sitting on the sidelines. Malhotra refers to Big Tech as the “new East India Company” and even coined the term ‘data-capitalism’ to describe how it hampers India's economic growth.
Should we have an Indian version of ChatGPT? It would entail significant computational investments for an unproven technology without immediate return on investments. A big problem is that the relevant datasets for India are in Indian languages, and no one is trying to use them. The Indian research community can also apply mathematical aphorisms to determine the correlative versus causative effects.
Generative LLM has limited potential uses in medicine, e.g., to improve data entries in electronic medical records and act as a “research assistant” in the clinic. However, this will require audit trails and transparency about input sources. Surely the use cases will increase, not only in medicine but in all sorts of areas, including search, journalism, programming, and so on.
Perhaps what we are seeing here is a massive churn in epistemology itself. There are valuable insights in Ayurveda that need to be incorporated into the Indian medical system. For instance, regarding the theory of disease, Allopathy is beginning to use genetic data in its diagnostic mechanisms. Gut microbiome is potentially pathognomonic for auto-immune diseases, diabetes and even Alzheimer’s.
The creation of medical knowledge based on stochastic assumptions is now subject to a violent change, as new paradigms are emerging. We could end up with very personalised medicine, as we can now collect enormous amounts of data on an ongoing basis, enough to create 'digital medical twins' of our bodies. Our genome can be used to understand our susceptibility to diseases, or to be modified with CRISPR-Cas9 to avoid them. Highly customized treatments are converging towards the premise in Ayurveda: treat disease and not symptoms. Or even the individual, not the disease.
Similarly, we are at an inflection point in the use and misuse of data by artificial intelligences. Yes, we have more data than ever before, and we can use Big Data and AI to form hypotheses about reality. However, the complexity itself may defeat us unless we can somehow choose the right parameters. Robert Sapolsky of Stanford in his book Behave suggests that there are very large numbers of factors that influence human behavior; it is impossible to capture these independent variables in a correlation model.
Our inability to ensure that we have captured all the relevant parameters, or even any of them, makes stochastic systems dangerous if you treat them as deterministic and unfailing oracles, which we tend to do. Stochastic systems are far from useless, but we must use them with caveats. We fail to do so with Allopathy, and we show every sign of doing the same with generative AI.
2540 words, 12 Mar 2023 updated 2610 words, 13 Mar 2023
Byline: Rajeev Srinivasan is a professor of innovation; Abhishek Puri is a radiation oncologist.
